
 root
079379557a
init
root
079379557a
init
|
2 éve | |
|---|---|---|
| .. | ||
| README_Ру́сский_язы́к.md | 2 éve | |
| README_हिन्द.md | 2 éve | |
| README_日本語.md | 2 éve | |
| README_한국어.md | 2 éve | |
README_Ру́сский_язы́к.md
English | 简体中文 | हिन्दी | 日本語 | 한국인 | Pу́сский язы́к

![]()

![]()
![]()



Введение
PaddleOCR стремится создавать многоязычные, потрясающие, передовые и практичные инструменты OCR, которые помогают пользователям обучать лучшие модели и применять их на практике



📣 Последние обновления
- 🔥2022.8.24 Выпуск PaddleOCR Выпуск /2.6
- Выпускать PP-Structurev2,с полностью обновленными функциями и производительностью, адаптированными для китайских сцен и новой поддержкой pаспознавание таблиц Восстановление макета и однострочная команда для преобразования PDF в Word;
- Анализ макета оптимизация: память модели уменьшена на 95%, а скорость увеличена в 11 раз, а среднее время процессорного времени составляет всего 41 мс;
- Распознавание таблиц оптимизация: разработано 3 стратегии оптимизации, а точность модели улучшена на 6% при сопоставимых затратах времени;
- Извлечение ключевой информации оптимизация: разработана визуально независимая структура модели, точность распознавания семантической сущности увеличена на 2,8%, а точность извлечения отношения увеличена на 9,1%.
- 🔥2022.7 Выпуск Коллекция приложений сцены OCR
- Выпуск 9 вертикальных моделей, таких как цифровая трубка, ЖК-экран, номерной знак, модель распознавания рукописного ввода, высокоточная модель SVTR и т. д., охватывающих основные вертикальные приложения OCR в целом, производственной, финансовой и транспортной отраслях.
- 🔥2022.5.9 Выпуск PaddleOCR Выпуск /2.5
- Выпускать PP-OCRv3: При сопоставимой скорости эффект китайской сцены улучшен на 5% по сравнению с ПП-OCRRv2, эффект английской сцены улучшен на 11%, а средняя точность распознавания 80 языковых многоязычных моделей улучшена более чем на 5%.
- Выпускать PPOCRLabelv2: Добавьте функцию аннотации для задачи распознавания таблиц, задачи извлечения ключевой информации и изображения неправильного текста.
- Выпустить интерактивную электронную книгу "Погружение в OCR", охватывает передовую теорию и практику кодирования технологии полного стека OCR.
- Выпускать PPOCRLabelv2: Добавьте функцию аннотации для задачи распознавания таблиц, задачи извлечения ключевой информации и изображения неправильного текста.
- подробнее
🌟 Функции
PaddleOCR поддерживает множество передовых алгоритмов, связанных с распознаванием текста, и разработала промышленные модели/решения. PP-OCR и PP-Structure на этой основе и пройти весь процесс производства данных, обучения модели, сжатия, логического вывода и развертывания.

⚡ Быстрый опыт
pip3 install paddlepaddle # for gpu user please install paddlepaddle-gpu
pip3 install paddleocr
paddleocr --image_dir /your/test/image.jpg --lang=ru
Если у вас нет среды Python, выполните Подготовка среды. Мы рекомендуем вам начать с Учебники.
📚 Электронная книга: Погружение в OCR
👫 Сообщество
Что касается международных разработчиков, мы рассматриваем Обсуждения PaddleOCR как нашу платформу для международного сообщества. Все идеи и вOCRосы можно обсудить здесь на английском языке.
🛠️ Список моделей серии ПП -OCR
| Введение модели | Название модели | Рекомендуемая сцена | Модель обнаружения | Модель распознавания |
|---|---|---|---|---|
| Ру́сский язы́к:Ру́сский язы́к Сверхлегкая модель ПП-OCRv3 (13.4M) | cyrillic_PP-OCRv3_xx | Мобильный и сервер | модель вывода/обученный модель | модель вывода/обученный модель |
| Английский сверхлегкая модель ПП-OCRv3 (13,4 Мб) | en_ПП-OCRv3_xx | Мобильный и сервер | модель вывода / обученный модель | вывод модель / обученный модель |
| Сверхлегкая китайская и английская модель ПП-OCRv3 (16,2M) | ch_ПП-OCRv3_xx | Мобильный и сервер | вывод модель / обученный модель | вывод модель / обученный модель |
- Для получения дополнительных загрузок моделей (включая несколько языков) см. Загрузки моделей серии ПП-OCR.
- Для запроса нового языка см Руководство для новых языковых_запросов.
- Модели структурного анализа документов см PP-Structure модельs.
📖 Учебники
- Подготовка окружающей среды
Аннотации и синтез данных
Наборы данных
🇺🇳 Руководство по запросам на новый язык
Если вы хотите запросить новую языковую модель, проголосуйте в Голосуйте за обновление многоязычной модели. Мы будем регулярно обновлять модель по результату. Пригласите друзей проголосовать вместе!
Если вам нужно обучить новую языковую модель на основе вашего сценария, учебное пособие в Проекте обучения многоязычной модели поможет вам подготовить набор данных и показать вам весь процесс шаг за шагом.
Оригинальный Многоязычный план разработки OCR по-прежнему показывает вам много полезных корпусов и словарей.
👀 Визуализация больше
PP-OCRv3 Многоязычная модель


PP-OCRv3 Aнглийская модель

PP-OCRv3 Kитайская модель

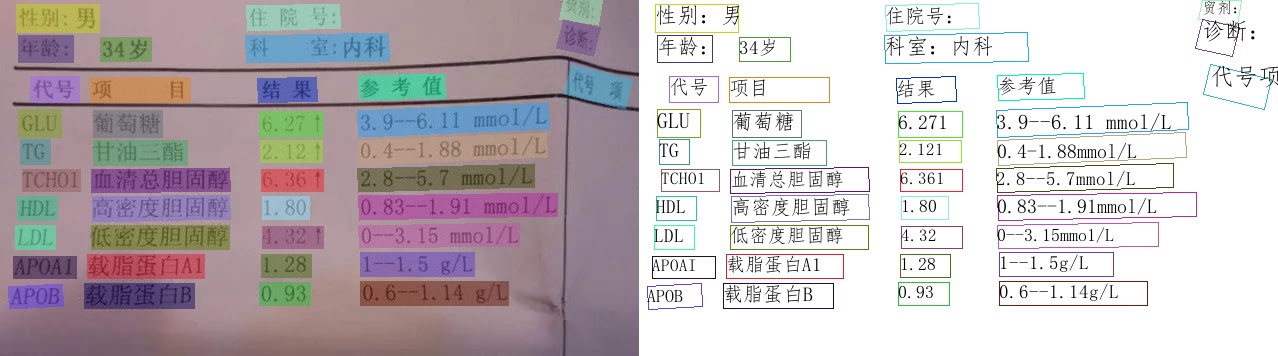

PP-Structurev2
1. анализ макета + распознавание таблиц






📄 Лицензия
Этот проект выпущен под Apache 2.0 license