
README_हिन्द.md 21 KB
English | 简体中文 | हिन्दी | 日本語 | 한국인 | Pу́сский язы́к

![]()

![]()
![]()



प्रस्तावना
पैडलओसीआर का उद्देश्य बहुभाषी,शानदार , ओसीआर और व्यावहारिक ओसीआरउपकरण बनाना है जो यूजर्स को बेहतर मॉडलों के लिए प्रशिक्षित करने और उन्हें व्यवहार में लागू करने में मदद करते हैं।



📣 हाल के अद्यतन
🔥2022.8.24 रिलीज Paddleओसीआर रिलीज/2.6
- रिलीज PP-Structurev2,फंक्शन और परफॉरमेंस के साथ पूरी तरह से उन्नत, चायनीज शीन्स के अनुकूल, और मदद के लिए लेआउट रिकवरी और पीडीएफ को वर्ड में बदलने के लिए वन लाइन कमांड;
- लेआउट एनालाइस ऑप्टिमाइजेशन: मॉडल स्टोरेज में 95% की कमी, जबकि स्पीड में 11 गुना वृद्धि , और एवरेज CPU स टाइम-कॉस्ट केवल 41ms है;
- टेबल रिकोगनाइजेशन ऑप्टिमाइजेशन: 3 ऑप्टिमाइज़ेशन के तरीके डिजाइन किए गए हैं, और तुलनात्मक समय की खपत के तहत मॉडल सटीकता में 6% का सुधार हुआ है;
- की इंफॉर्मेशन एक्स्ट्रेक्शन ऑप्टिमाइजेशन : एक बिजुवल-स्वतंत्र मॉडल संरचना डिजाइन की गई है, सिमेंटिक एन्टाइटी रिकग्निशन की सटीकता में 2.8% की वृद्धि हुई है, और रिलेशन एक्सट्रैक्शन की सटीकता में 9.1% की वृद्धि हुई है।
🔥2022.7 रिलीज ओसीआर दृश्य आवेदन संग्रह
- रिलीज 9 वर्टिकल मॉडल जैसे कि डिजिटल ट्यूब, एलसीडी स्क्रीन, लाइसेंस प्लेट, हस्तलेखन पहचान मॉडल, उच्च-सटीक एसवीटीआर मॉडल, आदि, जो सामान्य रूप से मुख्य ओसीआर वर्टिकल अनुप्रयोगों, विनिर्माण, वित्त और परिवहन उद्योगों को कवर करते हैं।
🔥2022.5.9 रिलीज Paddleओसीआर रिलीज/2.5
- रिलीज PP-OCRv3: तुलनात्मक स्पीड के साथ, चाइनीज शीन्स का प्रभाव PP-ओसीआर v2 की तुलना में 5% की और वृद्धि हुयी है इंगलिस शीन्स के प्रभाव में 11% का सुधार हुआ है, और 80 भाषाओं के बहुभाषी मॉडलों की औसत पहचान सटीकता में 5% से अधिक सुधार हुआ है।
रिलीज़ PPOCRLabelv2: टेबल टेबल रिकोगनाइजेशन टास्क की इंफॉर्मेशन एक्स्ट्रेक्शन टास्क और अनियमित टेक्सट इमेज के लिए एनोटेशन फ़ंक्शन एड करे।
इंटरएक्टिव ई-बुक जारी करें "ओसीआर में गोता लगाएँ", ओसीआर पूर्ण स्टैक तकनीक के अत्याधुनिक सिद्धांत और कोड प्रेक्टिस को कवर करता है।
🌟 विशेषताएँ
Paddleओसीआर से संबंधित विभिन्न प्रकार के अत्याधुनिक एल्गोरिथ्म को सपोर्ट करता है, और विकसित औद्योगिक विशेष रुप से प्रदर्शित मॉडल/समाधान PP- OCR और PP-Structure इस आधार पर और डेटा प्रोडक्शन की पूरी प्रोसेस के माध्यम से प्राप्त करें, मॉडल ट्रेनिंग, दबाव, अनुमान और तैनाती।

⚡ शीघ्र अनुभव
pip3 install paddlepaddle # for gpu user please install paddlepaddle-gpu
pip3 install paddleocr
paddleocr --image_dir /your/test/image.jpg --lang=hi
यदि आपके पास पायथन एनवायरनमेंट नहीं है, कृपया फॉलो कीजिए एनवायरनमेंट प्रिपेरेशन. हम अनुशंसा करते हैं कि आप इसके साथ शुरुआत करें ट्यूटोरियल.
📚 ई-बुक: ओसीआर में गोता लगाएँ
👫 समुदाय
अंतरराष्ट्रीय डेवलपर्स के लिए, हम सम्मान करते हैं पैडलओसीआर चर्चाएँ हमारे अंतरराष्ट्रीय कम्युनिटी मंच के रूप में। यहां सभी विचारों और प्रश्नों पर अंग्रेजी में चर्चा की जा सकती है।
🛠️ PP-ओसीआर श्रृंखला मॉडल सूची
| मॉडल प्रस्तावना | मॉडल नाम | रिकमेंडिड सीन | डिटेक्शन मॉडल | रिकोगनाइजेशन मॉडल |
|---|---|---|---|---|
| हिन्दी:हिन्दी अल्ट्रा-लाइटवेट PP-ओसीआरv3 सिस्टम (9.9M) | devanagari_PP-ओसीआरv3_xx | मोबाइल और सर्वर | इन्फरन्स मॉडल / प्रशिक्षितमॉडल | इन्फरन्समॉडल / प्रशिक्षित मॉडल |
| इंग्लिश अल्ट्रा- लाइट वेट PP-ओसीआरv3 मॉडल (13.4M) | en_PP-ओसीआरv3_xx | मोबाइल और सर्वर | इन्फरन्स मॉडल / प्रशिक्षितमॉडल | इन्फरन्समॉडल / प्रशिक्षित मॉडल |
| चाइनीस और इंग्लिश अल्ट्रा- लाइट वेट PP-ओसीआरv3 मॉडल(16.2M) | ch_PP-ओसीआरv3_xx | मोबाइल और सर्वर | इन्फरन्स मॉडल / प्रशिक्षित मॉडल | प्रशिक्षित मॉडल / प्रशिक्षित मॉडल |
- अधिक मॉडल डाउनलोड (एकाधिक भाषाओं सहित) के लिए, कृपया PP-ओसीआर सीरीज मॉडल डाउनलोड देखें।
- एक नए भाषा अनुरोध के लिए, कृपया नई भाषा अनुरोधों के लिए दिशानिर्देश.
- स्ट्रक्चर मॉडल डोकोमेंट एनालाइज के लिए, कृपया देखें PP-Structure models.
📖 ट्यूटोरियल
- एनवायरनमेंट प्रिपरेशन
- PP-OCR 🔥
- PP-Structure 🔥
- एकेडमिक एल्गोरिथम
- डेटा एनोटेशन और सिंथेसिस
- डेटा सेट
- कोड संरचना
- विसुमलाइजेशन
- कम्युनिटी
- नई भाषा के लिए अनुरोध
- सामान्य प्रश्न
- रेफरेन्सेस
- लाइसेंस
🇺🇳 नई भाषा अनुरोधों के लिए संयुक्त राष्ट्र दिशानिर्देश
अगर आप एक नए भाषा मॉडल का अनुरोध करना चाहते हैं, तो कृपया बहुभाषी मॉडल अपग्रेड के लिए वोट करें में वोट करें। हम नियमित रूप से परिणाम के अनुसार मॉडल को अपग्रेड करेंगे। अपने दोस्तों को एक साथ वोट करने के लिए आमंत्रित करें!
यदि आपको एक नए भाषा मॉडल को प्रशिक्षित करने अपने परिदृश्य के आधार पर, तो यह बहुभाषी मॉडल ट्रेनिंग प्रोजेक्ट ट्रेनिंग ट्यूटोरियल आपको डेटासेट तैयार करने में मदद करेगा और आपको स्टेप बाए स्टेप पूरा प्रोसेस दिखाएगा
मूल बहुभाषी ओसीआर विकास योजना अभी भी आपको बहुत सारे उपयोगी संग्रह और शब्दकोश दिखाता है
👀 विज़ुअलाइज़ेशन अधिक
PP-OCRv3 बहुभाषी मॉडल


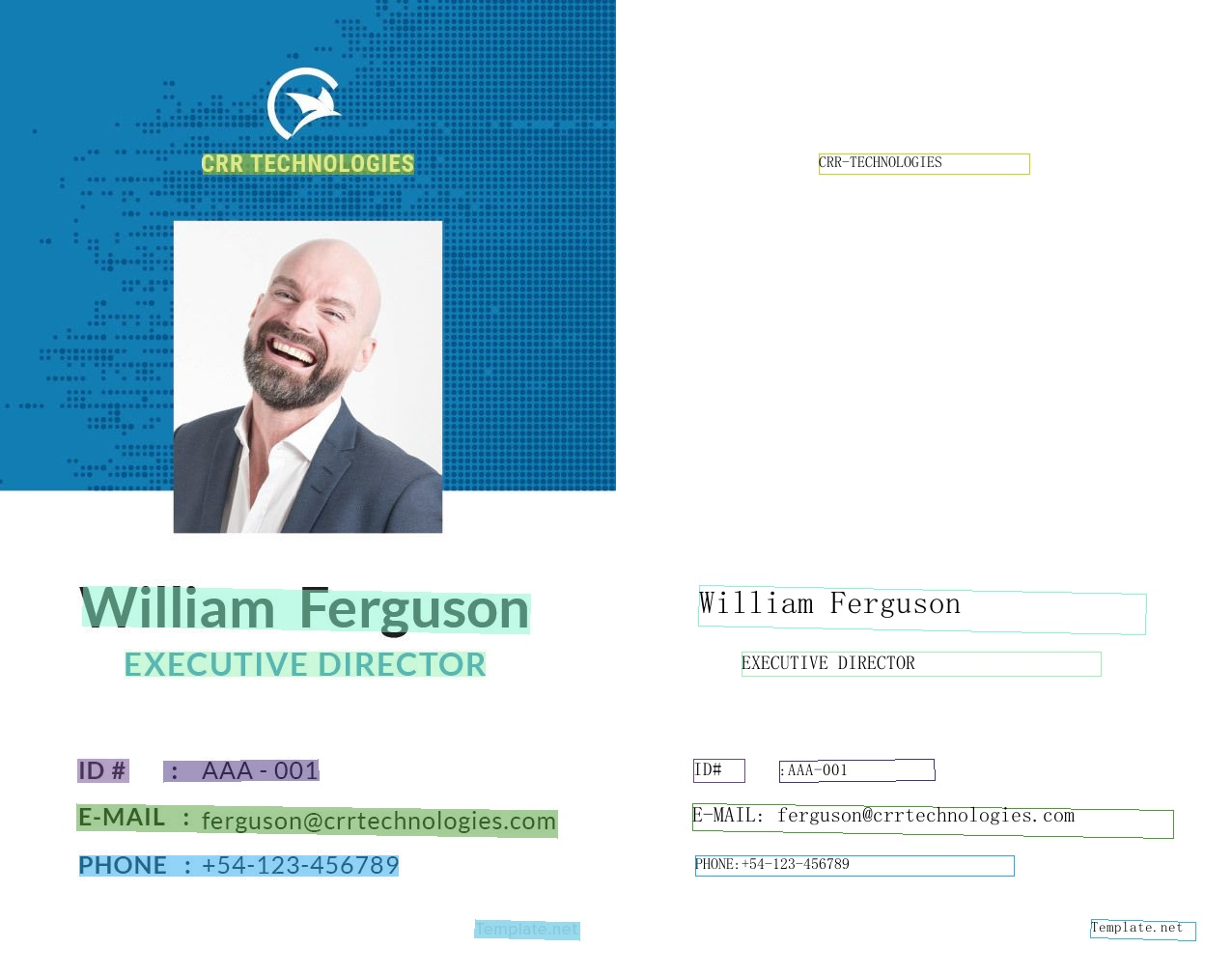
PP-OCRv3 अंग्रेजी मॉडल

PP-OCRv3 चीनी मॉडल

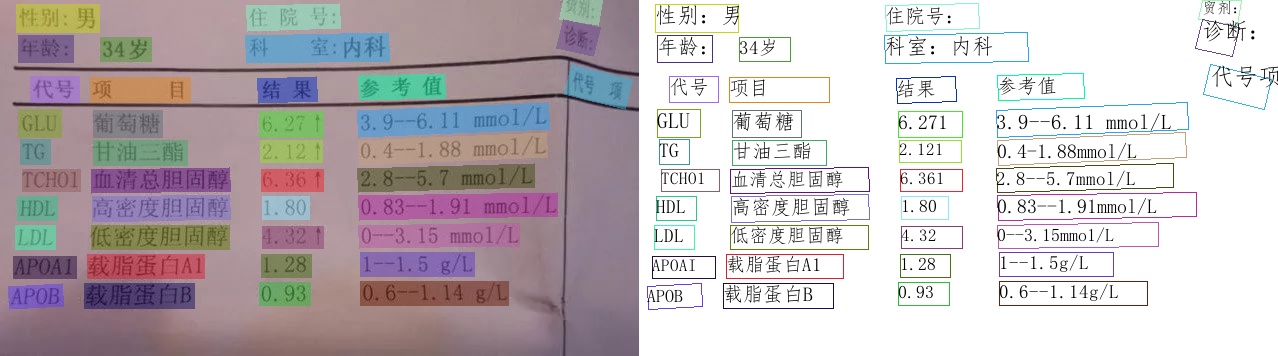

PP-Structurev2
1. लेआउट एनालाइस + टेबल रिकोगनाइजेशन






📄 लाइसेंस
इस प्रोजेक्ट को इन परियोजना के तहत जारी किया गया है Apache 2.0 license