# 基于Python引擎的PP-OCR模型库推理
本文介绍针对PP-OCR模型库的Python推理引擎使用方法,内容依次为文本检测、文本识别、方向分类器以及三者串联在CPU、GPU上的预测方法。
- [基于Python引擎的PP-OCR模型库推理](#基于python引擎的pp-ocr模型库推理)
- [1. 文本检测模型推理](#1-文本检测模型推理)
- [2. 文本识别模型推理](#2-文本识别模型推理)
- [2.1 超轻量中文识别模型推理](#21-超轻量中文识别模型推理)
- [2.2 英文识别模型推理](#22-英文识别模型推理)
- [2.3 多语言模型的推理](#23-多语言模型的推理)
- [3. 方向分类模型推理](#3-方向分类模型推理)
- [4. 文本检测、方向分类和文字识别串联推理](#4-文本检测方向分类和文字识别串联推理)
- [5. TensorRT推理](5-TensorRT推理)
## 1. 文本检测模型推理
文本检测模型推理,默认使用DB模型的配置参数。超轻量中文检测模型推理,可以执行如下命令:
```
# 下载超轻量中文检测模型:
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
tar xf ch_PP-OCRv3_det_infer.tar
python3 tools/infer/predict_det.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/"
```
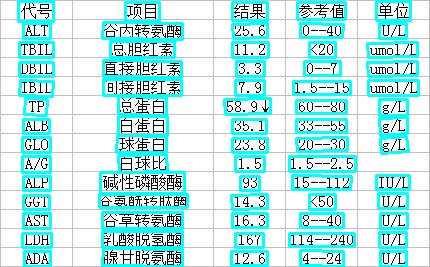
可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
通过参数`limit_type`和`det_limit_side_len`来对图片的尺寸进行限制,
`limit_type`可选参数为[`max`, `min`],
`det_limit_size_len` 为正整数,一般设置为32 的倍数,比如960。
参数默认设置为`limit_type='max', det_limit_side_len=960`。表示网络输入图像的最长边不能超过960,
如果超过这个值,会对图像做等宽比的resize操作,确保最长边为`det_limit_side_len`。
设置为`limit_type='min', det_limit_side_len=960` 则表示限制图像的最短边为960。
如果输入图片的分辨率比较大,而且想使用更大的分辨率预测,可以设置det_limit_side_len 为想要的值,比如1216:
```bash
python3 tools/infer/predict_det.py --image_dir="./doc/imgs/1.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/" --det_limit_type=max --det_limit_side_len=1216
```
如果想使用CPU进行预测,执行命令如下
```bash
python3 tools/infer/predict_det.py --image_dir="./doc/imgs/1.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/" --use_gpu=False
```
## 2. 文本识别模型推理
### 2.1 超轻量中文识别模型推理
**注意** `PP-OCRv3`的识别模型使用的输入shape为`3,48,320`, 如果使用其他识别模型,则需根据模型设置参数`--rec_image_shape`。此外,`PP-OCRv3`的识别模型默认使用的`rec_algorithm`为`SVTR_LCNet`,注意和原始`SVTR`的区别。
超轻量中文识别模型推理,可以执行如下命令:
```
# 下载超轻量中文识别模型:
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
tar xf ch_PP-OCRv3_rec_infer.tar
python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/ch/word_4.jpg" --rec_model_dir="./ch_PP-OCRv3_rec_infer/"
```

执行命令后,上面图像的预测结果(识别的文本和得分)会打印到屏幕上,示例如下:
```bash
Predicts of ./doc/imgs_words/ch/word_4.jpg:('实力活力', 0.9956803321838379)
```
### 2.2 英文识别模型推理
英文识别模型推理,可以执行如下命令, 注意修改字典路径:
```
# 下载英文数字识别模型:
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar
tar xf en_PP-OCRv3_rec_infer.tar
python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./en_PP-OCRv3_rec_infer/" --rec_char_dict_path="ppocr/utils/en_dict.txt"
```

执行命令后,上图的预测结果为:
```
Predicts of ./doc/imgs_words/en/word_1.png: ('JOINT', 0.998160719871521)
```
### 2.3 多语言模型的推理
如果您需要预测的是其他语言模型,可以在[此链接](./models_list.md#%E5%A4%9A%E8%AF%AD%E8%A8%80%E8%AF%86%E5%88%AB%E6%A8%A1%E5%9E%8B)中找到对应语言的inference模型,在使用inference模型预测时,需要通过`--rec_char_dict_path`指定使用的字典路径, 同时为了得到正确的可视化结果,需要通过 `--vis_font_path` 指定可视化的字体路径,`doc/fonts/` 路径下有默认提供的小语种字体,例如韩文识别:
```
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/korean_mobile_v2.0_rec_infer.tar
python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/korean/1.jpg" --rec_model_dir="./your inference model" --rec_char_dict_path="ppocr/utils/dict/korean_dict.txt" --vis_font_path="doc/fonts/korean.ttf"
```

执行命令后,上图的预测结果为:
``` text
Predicts of ./doc/imgs_words/korean/1.jpg:('바탕으로', 0.9948904)
```
## 3. 方向分类模型推理
方向分类模型推理,可以执行如下命令:
```
# 下载超轻量中文方向分类器模型:
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
tar xf ch_ppocr_mobile_v2.0_cls_infer.tar
python3 tools/infer/predict_cls.py --image_dir="./doc/imgs_words/ch/word_4.jpg" --cls_model_dir="ch_ppocr_mobile_v2.0_cls_infer"
```

执行命令后,上面图像的预测结果(分类的方向和得分)会打印到屏幕上,示例如下:
```
Predicts of ./doc/imgs_words/ch/word_4.jpg:['0', 0.9999982]
```
## 4. 文本检测、方向分类和文字识别串联推理
**注意** `PP-OCRv3`的识别模型使用的输入shape为`3,48,320`, 如果使用其他识别模型,则需根据模型设置参数`--rec_image_shape`。此外,`PP-OCRv3`的识别模型默认使用的`rec_algorithm`为`SVTR_LCNet`,注意和原始`SVTR`的区别。
以超轻量中文OCR模型推理为例,在执行预测时,需要通过参数`image_dir`指定单张图像或者图像集合的路径,也支持PDF文件、参数`det_model_dir`,`cls_model_dir`和`rec_model_dir`分别指定检测,方向分类和识别的inference模型路径。参数`use_angle_cls`用于控制是否启用方向分类模型。`use_mp`表示是否使用多进程。`total_process_num`表示在使用多进程时的进程数。可视化识别结果默认保存到 ./inference_results 文件夹里面。
```shell
# 使用方向分类器
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/" --cls_model_dir="./cls/" --rec_model_dir="./ch_PP-OCRv3_rec_infer/" --use_angle_cls=true
# 不使用方向分类器
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/" --rec_model_dir="./ch_PP-OCRv3_rec_infer/" --use_angle_cls=false
# 使用多进程
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/" --rec_model_dir="./ch_PP-OCRv3_rec_infer/" --use_angle_cls=false --use_mp=True --total_process_num=6
# 使用PDF文件,可以通过使用`page_num`参数来控制推理前几页,默认为0,表示推理所有页
python3 tools/infer/predict_system.py --image_dir="./xxx.pdf" --det_model_dir="./ch_PP-OCRv3_det_infer/" --cls_model_dir="./cls/" --rec_model_dir="./ch_PP-OCRv3_rec_infer/" --use_angle_cls=true --page_num=2
```
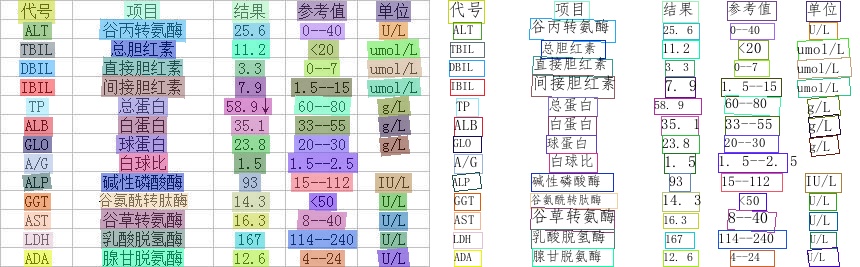
执行命令后,识别结果图像如下:
更多关于推理超参数的配置与解释,请参考:[模型推理超参数解释教程](./inference_args.md)。
## 5. TensorRT推理
Paddle Inference 采用子图的形式集成 TensorRT,针对 GPU 推理场景,TensorRT 可对一些子图进行优化,包括 OP 的横向和纵向融合,过滤冗余的 OP,并为 OP 自动选择最优的 kernel,加快推理速度。
如果希望使用Paddle Inference进行TRT推理,一般需要2个步骤。
* (1)收集该模型关于特定数据集的动态shape信息,并存储到文件中。
* (2)加载动态shape信息文件,进行TRT推理。
以文本检测模型为例,首先使用下面的命令,生成动态shape文件,最终会在`ch_PP-OCRv3_det_infer`目录下面生成`det_trt_dynamic_shape.txt`的文件,该文件即存储了动态shape信息的文件。
```bash
python3 tools/infer/predict_det.py --image_dir="./doc/imgs/1.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/" --use_tensorrt=True
```
上面的推理过程仅用于收集动态shape信息,没有用TRT进行推理。
运行完成以后,再使用下面的命令,进行TRT推理。
```bash
python3 tools/infer/predict_det.py --image_dir="./doc/imgs/1.jpg" --det_model_dir="./ch_PP-OCRv3_det_infer/" --use_tensorrt=True
```
**注意:**
* 如果在第一步中,已经存在动态shape信息文件,则无需重新收集,直接预测,即使用TRT推理;如果希望重新生成动态shape信息文件,则需要先将模型目录下的动态shape信息文件删掉,再重新生成。
* 动态shape信息文件一般情况下仅需生成一次。在实际部署过程中,建议首先在线下验证集或者测试集合上生成好,之后可以直接加载该文件进行线上TRT推理。